Instructions for using Waggawagga
Input mask
In the following section the single components of the user interface will shortly be presented. Simply spoken the user interface is divided in two main parts: The input mask at the top of the page and the result section of the analysis below.
The web-based user interface provides an input form, which enables the user to upload protein sequences in plain-text or as FASTA-formatted text. On the server-side the sequence is pre-processed to filter out gaps, special characters, numbers, etc. In general characters, which does not match the FASTA-format. A specification of the FASTA-format can be found here. For demonstration purposes there are two examples, which can be loaded instead of an own protein sequence.
As a next step, the coiled-coil prediction tools can be chosen out of two sets: The classic prediction tools, which deliver as a result probable coiled-coil regions, and the extended tools, which predict several types of oligomerization states on basis of the previous prediction results. Another feature, which can be customized, is the used window-length of the prediction tools. It directly influences the predicted region by smoothing the predictions with increasing windows-length, which can be 14, 21 and 28.
Result section
The result section is grouped into four subsections, which present the analysed protein sequence data in different ways. After finishing the calculation of the results, the user can find a unique
Domain Overview
The first subsection is the domain view, which lists an abstract sequence overview for all submitted protein sequences in combination with the selected prediction tools. Predicted coiled-coil regions are highlighted. Each sequence has an interactive slider for changing the viewable region of the current sequence. By moving the slider, the illustrations below alter instantaniously/accordingly.

Click figure to enlarge
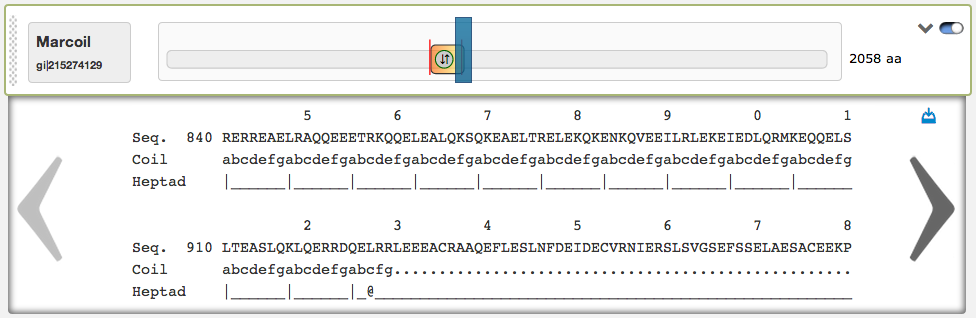
The domain view has several functions to interact with: The first figure shows the predicted coiled-coil regions for the tool Marcoil, which were calculated for the example protein sequence
| 2 | General dimer | ⇈ | Parallel dimer | ⇵ | Antiparallel dimer |
| 3 | Trimer | 4 | Tetramer | • | Combined information in case a box doesn't provide enough space |
The predicted coiled-coil regions may contain shifts in the heptad motives, which are indicated by red lines. Shift positions can be detected by hovering with the mouse above them. The domain view contains an interactive slider that influences the rendered regions in the illustrations below (
On the right side of the domain view are two buttons: The left of them opens a textual result of the prediction, that is very useful to see the predicted coiled-coil regions and heptad patterns aligned to the protein sequence. By clicking on the left/right arrows, the user can scroll through the textual result. Here is also an automatic scrolling available, the textual result automatically jumps to the corresponding sequence position, when the according slider is dragged around. In the top-right corner of the textual result box is a download link. The up/down-pointing arrow-button can be used to fade in/out the textual result.
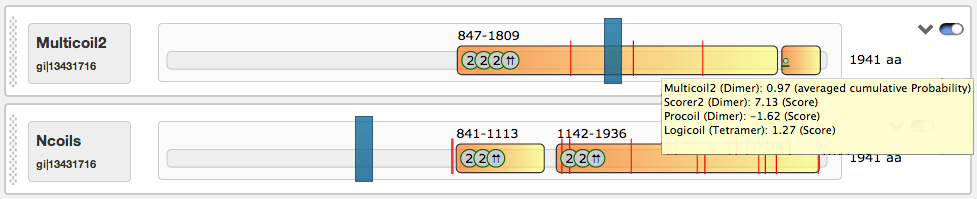
Finally the most right button in the domain view is a switch to turn the slider into an inactive state, so that the single coiled-coil regions are directly clickable. An example for this function is given in the figure below. When inactived, the slider turns into grey color and is not draggable anymore. The current active region is highlighted then in blue.

Click figure to enlarge
Configuration
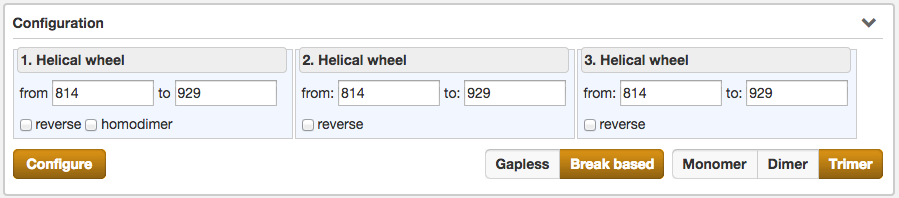
Another part of the result section is the Configuration, which enables the user to fine-tune the selected protein sequence region for the Helical wheel view.
Click figure to enlarge
Configurations, which can be made, are the selection of the type of the helical wheel diagram. The
user can choose between Monomer, Dimer or Trimer views. By switching between them, the illustration below alters
instantaniously. Further functions are the precise specification of the sequence range for the wheels of
the helical wheel diagram, the direction (
Helical wheel view
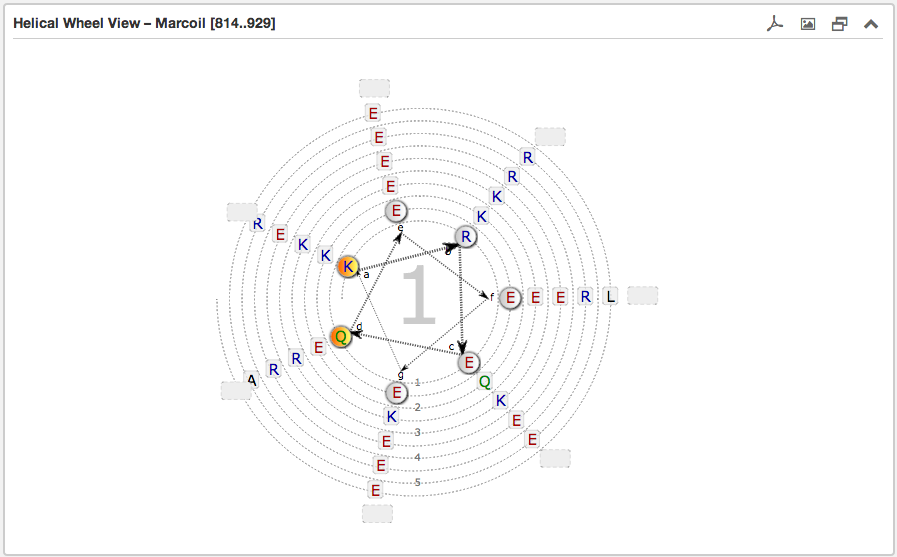
The second main subsection is the Helical wheel view. This view is designed to
visualize the possible residue interactions inside a predicted coiled-coil. The view is capable to depict the three above mentioned coiled-coil types. The
helical wheel view can be customized "freely" in range, direction and oligomerization state
by using the above described Configuration form or simply by moving the slider along a
domain view, if the user wants quickly to shift over the sequence. The pre-selected windows-length
for the slider has a fixed size of 49.
Each wheel, representing a helix viewed from the top, is made up of seven groups [a and d are highlighted in orange and are oriented to the opposing wheel representing
the inner side of a coiled-coil helix. If there are more than six residues per heptad group, the
remaining residues are combined into an expandable bubble at the end of the group (outside the wheel). The group
can be expanded by clicking on it. If there are less than six residues per group, the SVG-based view shrinks
automatically the number of windings.

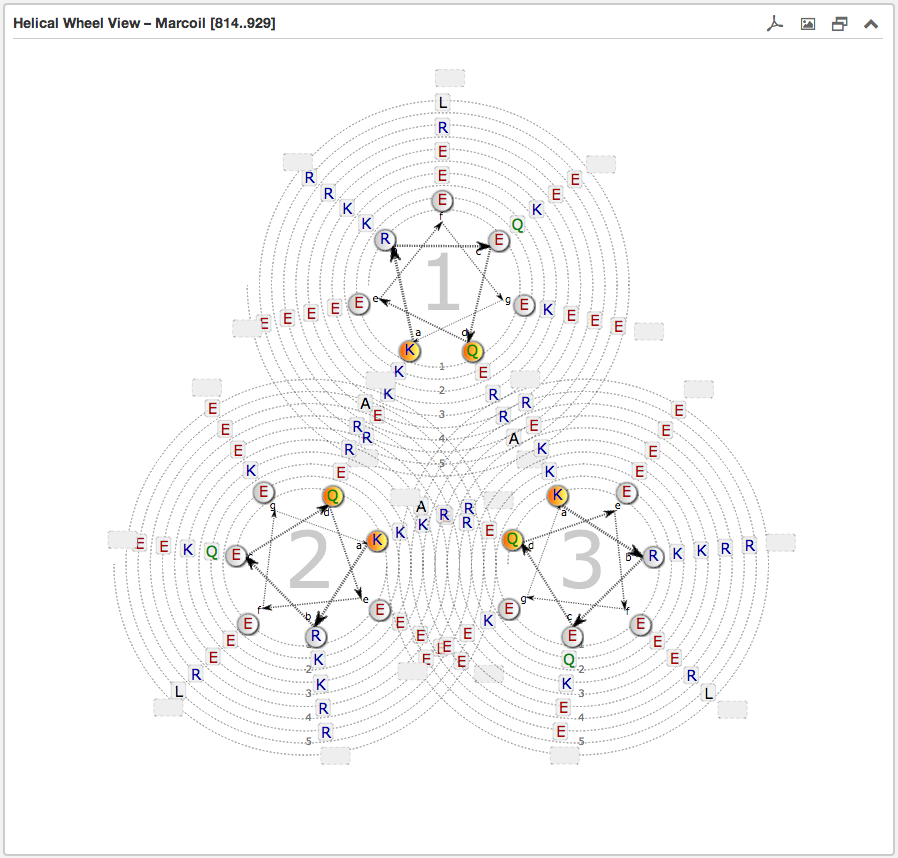
Click figures to enlarge
There are several common control icons, which occur repeatedly on the page. Declaring from left to right: The

Helical Net view and the Single-Alpha-Helix Score
The web-application
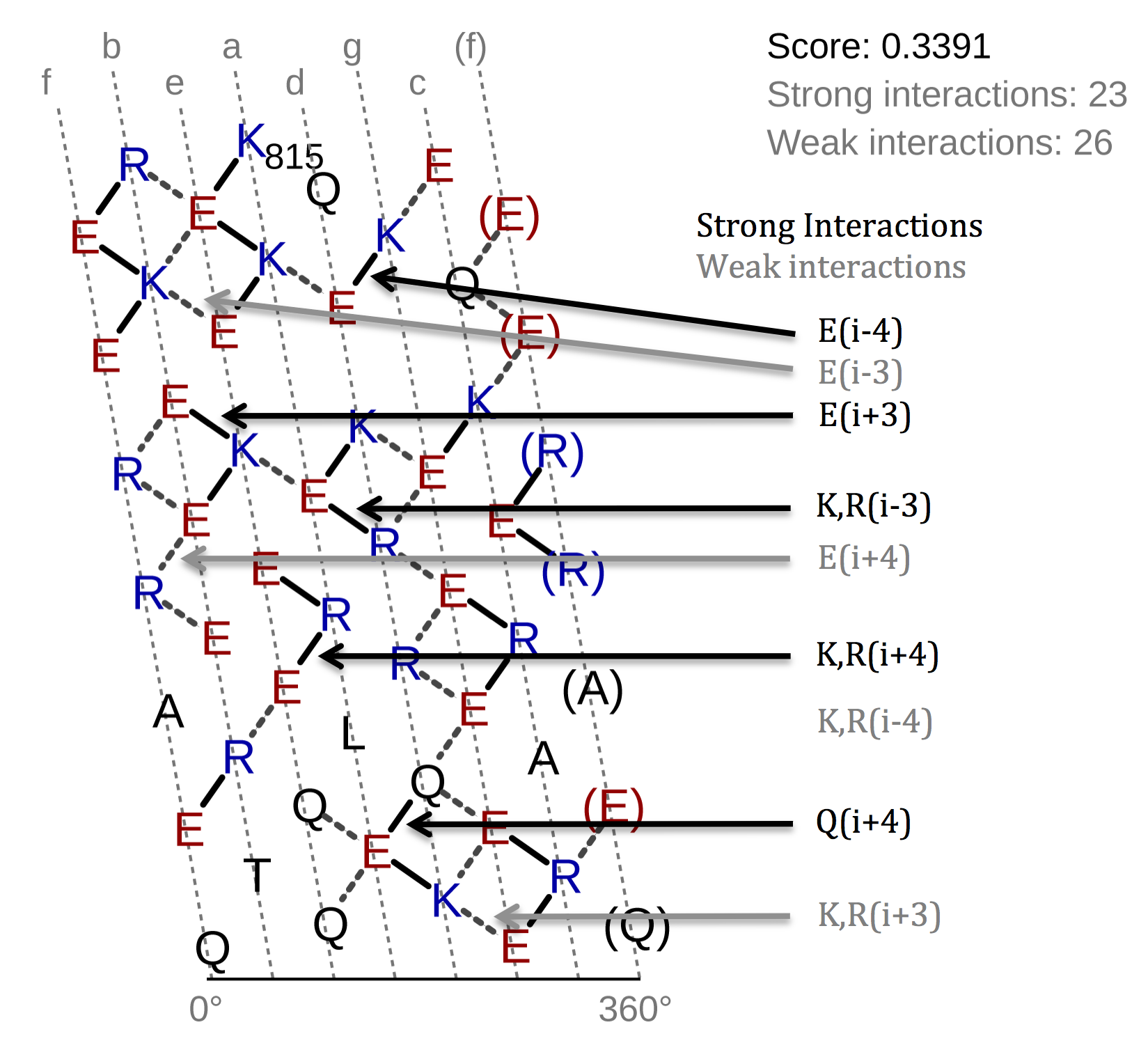
Click figure to enlarge
The helical net has to be read in rows always starting from right to left. Between interacting residues,
solid and dashed connections are drawn, which represent the strong and weak type of interactions. As you can see
from the figure above, the black drawn lines are strong interactions and the dashed grey ones are weak. The
classification of the interaction lines results from the rules, aside the helical net. For instance the black rule
In the top-right corner of the helical net view the SAH-score with the number of the strong and weak interactions
is displayed. On the left side of the helical net diagram an overview is depicted, which shall give an idea of the
position of selected region in the sequence and its surrounding residues.
| Source Residue | Target residue | Interaction | Score | |
|---|---|---|---|---|
| K/R | ⟹ | E/D | i+4; i+3 | 1.0 |
| D | ⟹ | K/R | i+4 i+3 | 0.75 0.5 |
| E | ⟹ | K/R | i+4; i+3 | 0.5 |
| Q | ⟹ | E/ | i+4; i+3 | 0.5 |
| E | ⟹ | Q | i+4; i+3 | 0.5 |
SAH-Scoring
Helices, that are not buried within globular structures or coiled-coil helix dimers with hydrophobic seams at their interfaces, need networks of charge interactions for stabilization in water. For example, poly-alanine peptides adopt α-helical conformations in water only when they contain oppositely charged residues in distances appropriate to form salt bridges. In the late 1980th and early 1990th many studies have been performed using such poly-alanine models aiming to resolve the conditions for helix formation and stabilization. Different amino acids (mainly Asp, Glu, Lys and Arg, but in some cases also Gln) were introduced in various combinations at varying distances, the corresponding peptides synthesised, their α-helicity experimentally determined by, for example, circular dichroism, and stabilization energies obtained by fitting models to the data.
According to these experiments, helices are stabilized by charged interactions (salt bridges) between residues at
Prediction results: GnuPlot and Tabular
In the last result subsection the computed analyses are presented as plotted graphs (GnuPlot) and as pure values
in the table aside. For each analysis there is a tab, which holds the relevant prediction data. The plot
combines both predictions (coiled-coil & according SAH) in one graph and visualizes the probabilities over the
length of the sequence. Filled areas in blue/red give a hint, as described in the legend of the figure below,
whether there is a probable coiled-coil or SAH region or not. This depends on the in dashed lines drawn thresholds.
Our values for the thresholds were chosen by analysing an annotated PDB-dataset, where the exact regions of
coiled-coils and single-alpha-helices were available.
Left to it are the prediction values listed in a table. Each line follows the structure: Sequence position, residue,
heptad pattern position, coiled-coil prediction probability and SAH prediction probabilility.
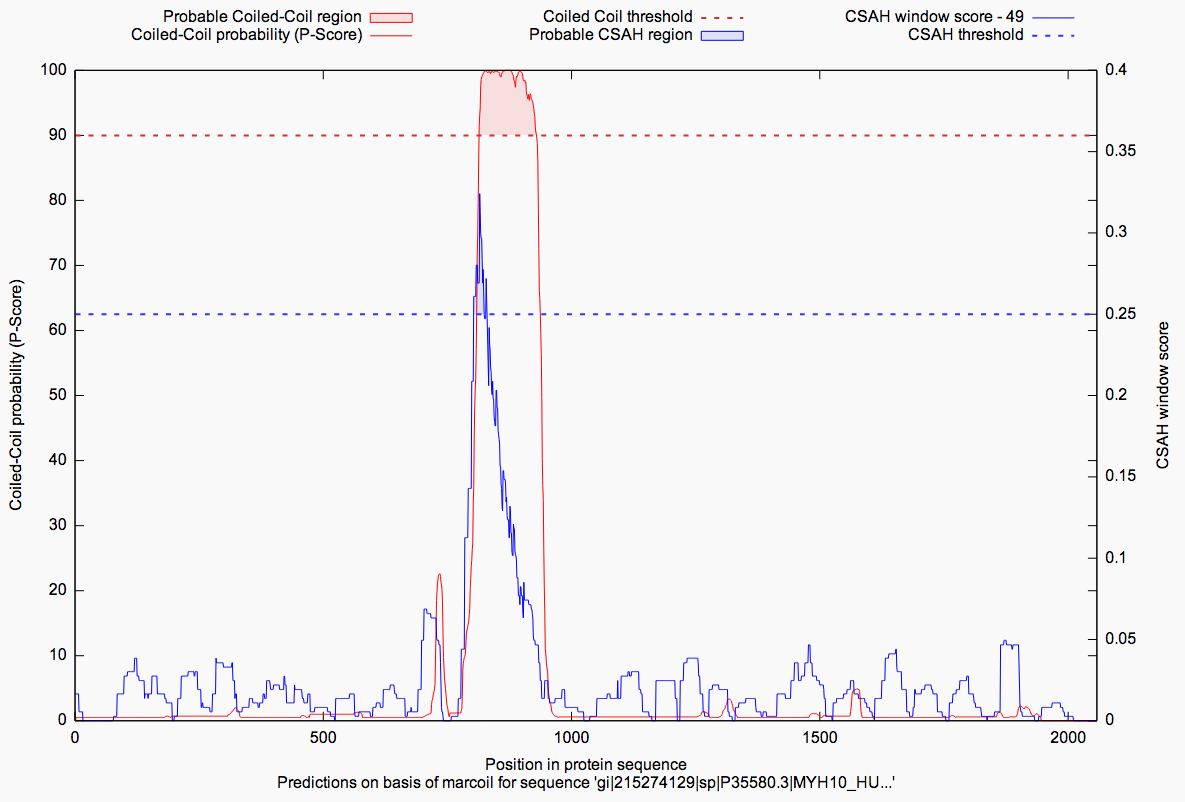
Click figure to enlarge
Rights and Restrictions
Using Waggawagga by non-academics requires permission. Waggawagga may be obtained upon request and used under a GNU General Public License.
References
This last section is a listing of all publications with methodical influence on the implementation of the scoring algorithm and the visualizations and of the software, which has been used to realize this service. The focus here lies mainly on the bioinformatic coiled-coil prediction tools.
Methodical References
[1] Marqusee S, Baldwin RL: Helix stabilization by Glu-...Lys+ salt bridges in short peptides of de novo design. Proc Natl Acad Sci U S A 1987, 84:8898–8902.
[2] Huyghues-Despointes BM, Scholtz JM, Baldwin RL: Helical peptides with three pairs of Asp-Arg and Glu-Arg residues in different orientations and spacings. Protein Sci Publ Protein Soc 1993, 2:80–85.
[3] Scholtz JM, Qian H, Robbins VH, Baldwin RL: The energetics of ion-pair and hydrogen-bonding interactions in a helical peptide. Biochemistry (Mosc) 1993, 32:9668–9676.
[4] Smith JS, Scholtz JM: Energetics of polar side-chain interactions in helical peptides: salt effects on ion pairs and hydrogen bonds. Biochemistry (Mosc) 1998, 37:33–40.
[5] Olson CA, Spek EJ, Shi Z, Vologodskii A, Kallenbach NR: Cooperative helix stabilization by complex Arg-Glu salt bridges. Proteins 2001, 44:123–132.
[6] Lyu PC, Marky LA, Kallenbach NR: The role of ion pairs in .alpha. helix stability: two new designed helical peptides. J Am Chem Soc 1989, 111:2733–2734.
[7] Lyu PC, Liff MI, Marky LA, Kallenbach NR: Side chain contributions to the stability of alpha-helical structure in peptides. Science 1990, 250:669–673.
[8] Michelle Peckham and Peter J Knight. 2009. When a predicted coiled coil is really a single α-helix, in myosins and other proteins. Soft Matter, 5: 2493–2503.
Software References
[1] Naohisa Goto, Pjotr Prins, Mitsuteru Nakao, Raoul Bonnal, Jan Aerts and Toshiaki Katayama. 2010. BioRuby. Bioinformatics, 26: 2617–2619.
[2] Lupas, A., Dyke, M. & Stock, J. (1991). Predicting coiled coils from protein sequences. Science, 252(5009), 1162-1164. - jstor.org/stable/2876291
[3] Delorenzi, M. & Speed, T. (2002). An HMM model for coiled-coil domains and a comparison with PSSM-based predictions. Bioinformatics, 18, 617–625.
- 10.1093/bioinformatics/18.4.617
[4] Kim, P. S., Berger, B. & Wolf, E. (1997). MultiCoil: A program for predicting two-and three-stranded coiled coils. Protein Science, 6, 1179–1189.
[5] Trigg, J., Gutwin, K., Keating, A. E. & Berger, B. (2011). Multicoil2: Predicting Coiled Coils and Their Oligomerization States from Sequence in the Twilight Zone. PLOS ONE, 6, 1–10.
[6] Berger, B., Wilson, D. B., Wolf, E., Tonchev, T., Milla, M. & Kim, P. S. (1995). Predicting Coiled Coils by Use of Pairwise Residue Correlations. Proceedings of the National Academy of Science USA, 92, 8259-8263.
[7] McDonnell, A. V., Jiang, T., Keating, A. E. & Berger, B. (2006) Paircoil2: improved prediction of coiled coils from sequence. Bioinformatics, 22: 356–358.
[8] Craig T Armstrong, Thomas L Vincent, Peter J Green and Derek N Woolfson. 2011. SCORER 2.0: An algorithm for distinguishing parallel dimeric and trimeric coiled- coil sequences. Bioinformatics, 27: 1908–1914.
[9] C C Mahrenholz, I G Abfalter, U Bodenhofer and R Volkmer. 2010. PrOCoil - Advances in predicting two-and three-stranded coiled coils. homo.
[10] Thomas L Vincent, Peter J Green and Derek N Woolfson. 2013. LOGICOIL — Multi-state prediction of coiled-coil oligomeric state. Bioinformatics, 29: 69–76.